Creating your first data pipeline with Python
The aim of this little project is to create a simple data pipeline. First, we will extract data from a subset of webpages. Then, we will proceed to clean and load this data into a database. Finally, we will visualize it with the help of a dashboard.
To provide some context, it is 2021 and there is a widespread semi-conductor shortage. This shortage is partly caused by the COVID-19 pandemic, partly by the cryptocurrency mining boom. As such, GPUs are extremely scarce; either hoarded by mining farms or bought by scalpers with the help of bots.
Here is a simple graph explaining the idea:

Let’s start with the Python script:
The basic gist of the script is:
1) Using the package bs4, we will scrape one of the webpages defined in the dictionary named “pages_dictionary”. Then, we will proceed to parse this information so that it fits into the schema defined by the dictionary named “details”.
2) Every time the information is parsed correctly it is added as an element of the list “sql_information_list”. We do this for each of the 11 different URLs.
3) Following this we check if any of the 11 results have the key ‘deal’ set as True. If this is the case; using the packages ‘smtplib’ and ‘ssl’ we send an email to notify us.
4) Finally, we load this information using the package psycopg2 into a Postgres database running inside a Docker container.
Alright, now we can proceed to create a Postgres database with Docker.
Docker:
We will be using the official Postgres image from Docker hub. We are simply creating a table inside the default database ‘postgres’ that is initialized when the container is created for the first time.
# I am assuming that you have docker already installed. Otherwise, Docker itself has a very straightforward guide on how to install @ https://docs.docker.com/get-docker/
The beauty of Docker is that you can install it in any OS and the commands I’ll use will work just the same# To create your docker container for the first time:
docker run -d -p 4321:5432 --name PostgresDB -e POSTGRES_PASSWORD=potatopotato postgres ## To enter into your your container:
docker exec -it PostgresDB bash # Once inside your container, to enter postgres:
psql -U postgres# Finally, to create the table:CREATE TABLE scraped_data (
date_of_scraping timestamp,
seller varchar(20),
name varchar(100),
price integer,
in_stock bool,
deal bool,
url varchar(100)
);
With your table created, it is time to automate your script.
Linux:
The simplest tool you can you is crontab. Here is an image showing you how it was set up.

Windows:
You can use Task Scheduler. Do note that you’ll have to use a .bat file to run the script.
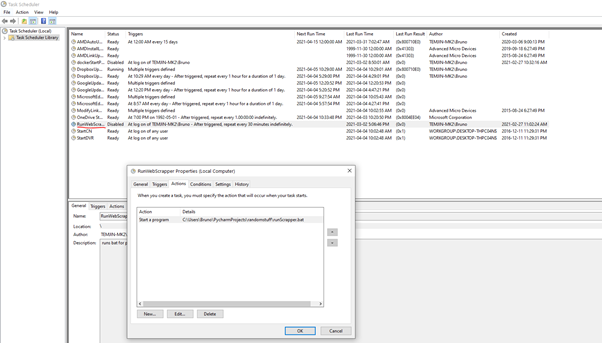
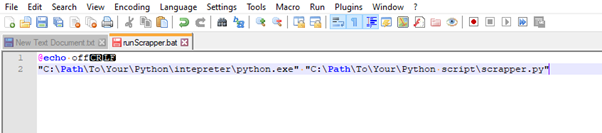
For this demonstration, we are running the script every 30 minutes. My reasoning is the following: If we scrape in a smaller timeframe, we could potentially trigger anti-bot measures; such as getting the IP temporarily blocked. Moreover, in my case we would fill the database very quickly; given it is running inside a minuscule SSD.
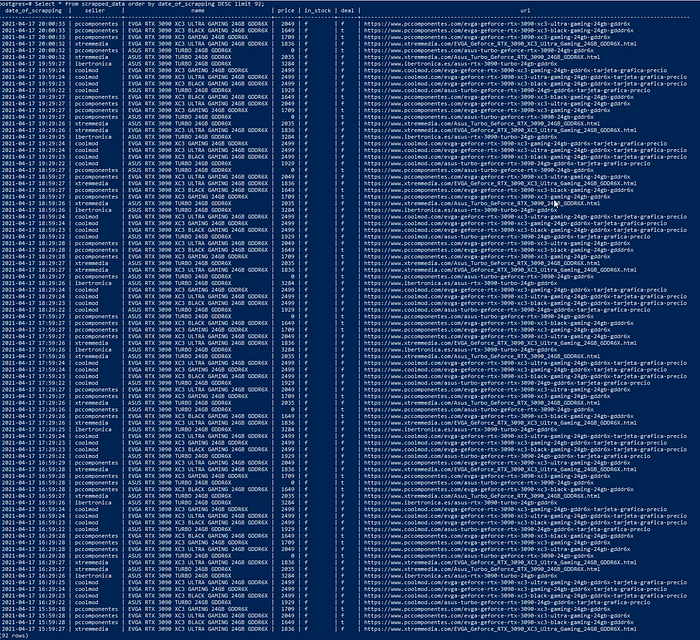
Once the script runs at least once, you should be able to see something like this in your table.
Dashboard:
For the purpose of this demonstration we are using Grafana, an open source monitoring tool and running inside a docker container.
# To create your Grafana container:
docker run -d -p 3000:3000 --name=grafana grafana/grafanaOnce the container is up and running,
- Open your web browser and go to http://localhost:3000/.
- On the login page, enter admin for username and password.
- Click Log In. Click OK on the prompt, then change your password.
- To add our Postgres DB as a data source refer to the picture below
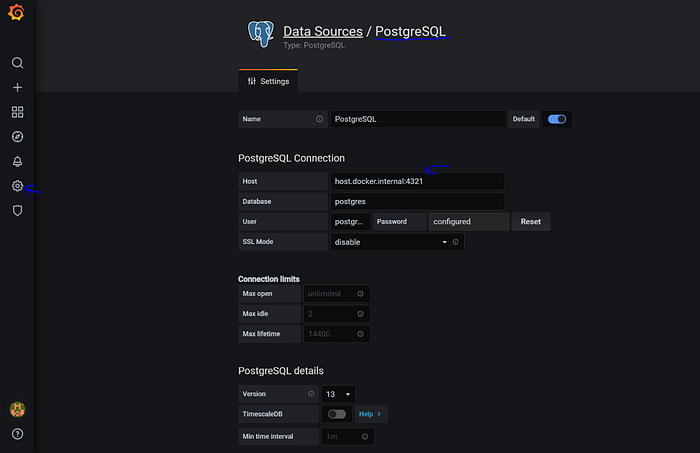
With your data source added, you can start creating your dashboard as you see fit. Here is a screenshot of the last version of my dashboard.
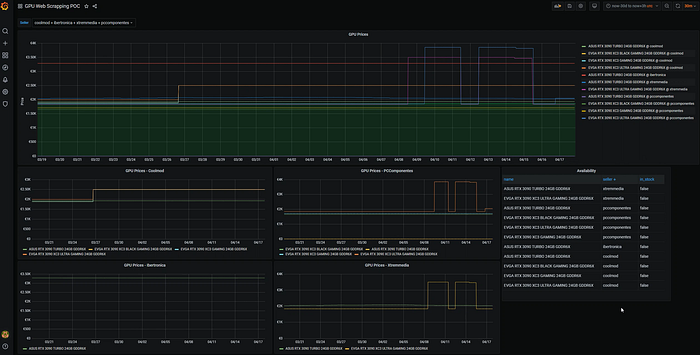
Voila, a simple data pipeline is created.
So in conclusion, what this pipeline has achieved is:
- It has extracted data from different websites via scraping.
- Then, it has transformed the data; cleaning it so that it can fit our desired Schema.
- Afterwards, it has loaded the cleaned data into a PostgreSQL database
- Finally, with the help of Grafana we have visualized the data in a simple dashboard.
ETL at its simplest.
